在大数据时代,我们每天都在制造海量的信息,包括发送的消息、拍摄的照片、社交媒体上的视频以及科研实验的数据等。根据调研机构 IDC 的预测,到 2028 年,全球每年产生的数据总量将超过 380 ZB(1ZB 约等于 1 万亿 GB),相当于 3800 亿块家用 1 TB 的移动硬盘所能存储的内容。
面对如此庞大的数据体量,我们目前使用的存储媒介,例如磁带、光盘和硬盘,正变得越来越难以满足需求。这些设备不仅容量有限,能耗高,而且寿命较短,导致大量数据都无法得到长期、可靠的保存。
为了应对这一挑战,科学家们开始探索新的存储方式,他们把目光投向了 DNA——这种存在于生物体内的分子,能够稳定地传递遗传信息长达数百万年。更重要的是,DNA 天然具有极高的存储密度和极低的能耗,这使其成为实现大规模、长期存储的潜在理想载体。
近期,国家生物信息中心应用发展部陈非研究团队与中国科学院计算技术研究所处理器全国重点实验室谭光明、卜东波团队、中科计算技术西部研究院段勃团队合作,设计出了一套全新的 DNA 存储系统,并将其命名为“毕昇一号”,以致敬中国古代活字印刷术的发明人毕昇。
毕昇一号以“DNA 活字”为核心,将数字信息“打印”到 DNA 之中,大幅降低了 DNA 存储的成本,为 DNA 存储的实用化带来了新的可能。
DNA 存储的原理与优势
要理解毕昇一号的创新之处,我们首先需要了解 DNA 存储本身的原理与优势。DNA,学名脱氧核糖核酸,是生命体中用于储存遗传信息的分子。
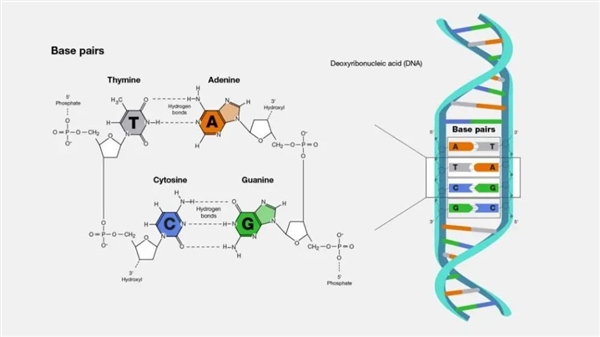
它的结构类似一条长链,其中包含四种碱基:A(腺嘌呤)、G(鸟嘌呤)、C(胞嘧啶)和 T(胸腺嘧啶)。这些碱基通过特定的方式配对排列,记录着生命体从外貌到功能的全部遗传信息。
下图展示了这四种碱基的配对方式:A 总是和 T 配对,C 总是和 G 配对,它们通过氢键连接,构成了 DNA 的基本单元。
DNA 的基本组成结构及四种碱基配对方式
给DNA装“活字” 我国自主研发“毕昇一号”实现存储技术跨越
在计算机中,各种形式的数据本质上都是以“ 0 ”和“ 1 ”组成的二进制串的形式存储的。DNA 存储的基本原理,就是将这些二进制信息转换为特定的碱基序列。例如,可以设定A对应“ 00 ”,G 对应“ 01 ”,C 对应“ 10 ”,T 对应“ 11 ”。
这样一来,任何文本、图片或视频都能被编码为一串 DNA 序列;通过人工合成这些序列,信息就被写入了 DNA 分子中。当需要读取数据时,再用 DNA 测序技术读取碱基的排列顺序,反向解码回二进制,就能还原出原始数据。与传统的存储设备相比,DNA 存储展现出多种显著优势。
首先是极高的数据密度。比如,人类基因组包含超过 30 亿个碱基对,但其重量仅为 3 皮克(1 皮克等于一万亿分之一克)。
其次,DNA 具有惊人的稳定性。在自然条件下,如果储存得当,它可以保存数万年不被破坏。科学家就曾成功从数万年前的猛犸象遗骸中提取出可读取的 DNA 序列,这一能力远远超过目前存储设备几十年的寿命。
最后,DNA 不依赖电力维持,不像传统的硬盘或服务器需要定期维护和持续供电,适用于保存长期数据。
近年来,DNA 的测序和合成技术都取得了巨大的进展,为 DNA 存储的可行性奠定了坚实的基础。在这样的背景下,科学家们开始尝试寻找更加高效和低成本的存储方式,让这一技术能够真正应用于现实。基于这一理念开发的“毕昇一号”系统,正是 DNA 存储向实用化迈出的关键一步。
从古老的活字印刷术到现代的“DNA 活字”存储术
活字印刷术是中国古代四大发明之一。在此之前,书籍的复制主要依靠雕版印刷,也就是为每一页内容单独雕刻一块书版。雕版印刷刻出一版后就可以印出无数份,但这种方法制作成本高、效率低、难以灵活调整内容。
直到北宋年间,中国发明家毕昇发明了活字印刷术,将雕版拆分为一个个可以重复使用的字块,在印刷时按需组合,用完后还可以拆卸保存,大大提升了排版效率。DNA 存储的发展也正在经历着类似的演变。
现有的 DNA 存储技术大多类似雕版印刷,需要为每个文件从头开始进行昂贵且耗时的一次性 DNA 合成。为了解决这一问题,研究团队从活字印刷术中获得灵感,创新性地提出了 DNA 活字的概念。他们设计出一套可以预制和复用的 DNA 片段,使 DNA 存储从“一次性合成”转变为“编码组装”,大幅降低了 DNA 合成和存储成本。
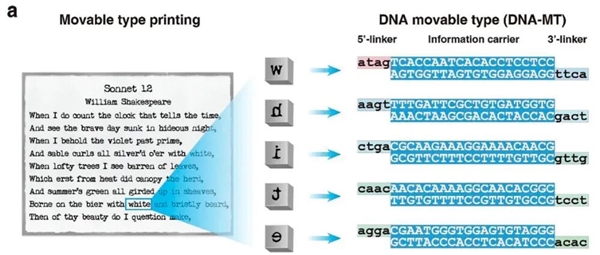
DNA 活字是一种预先合成好的短链 DNA 片段,每条片段中间含有 20 个用于存储信息的碱基对,两侧则带有专门设计的黏性末端(类似字块的“接口”)以用于连接。这种设计让每个 DNA 活字可以表示一个信息单元,也可以像字块一样自由组合、顺序拼接,最终存储一段完整的信息。
下图展示了五个 DNA 活字的结构示例,它们共同编码了莎士比亚的《十四行诗》中的单词“white”。每个 DNA 活字代表一个字母,而它们的黏性末端则确保这些字母按照正确顺序一一连接,最终拼出的长链就像印好的诗句一样,完整存储了目标信息。
DNA 活字(DNA-MT)(图片来源:参考文献[1])
给DNA装“活字” 我国自主研发“毕昇一号”实现存储技术跨越
毕昇一号:DNA 存储的活字打印机
为了将 DNA 活字这一理念真正变成现实,实现 DNA 存储的自动化,研究人员设计并搭建了 DNA 活字喷墨打印机——毕昇一号。这个系统结合了 DNA 活字与现代喷墨打印技术,装配有多个 DNA 墨盒,并内置摄像头和图像分析软件,用于实时检测喷墨过程中的故障,从而保证较高的成功率。

给DNA装“活字” 我国自主研发“毕昇一号”实现存储技术跨越
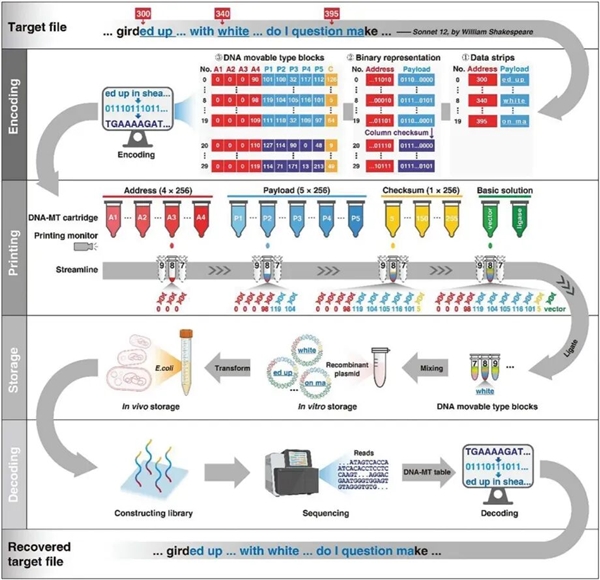
毕昇一号(图片来源:参考文献[1])毕昇一号实际工作流程分为四个关键步骤:编码、打印(组装)、存储和解码。第一步是编码。系统首先将需要存储的数据划分为若干较小的片段,并将其转换为二进制格式。
随后,这些二进制片段会被拆分为更小的信息单元,根据每个信息单元的内容,自动匹配相应的 DNA 活字。第二步是打印。这是毕昇一号的核心环节,它利用类似喷墨打印的技术,将 DNA 活字按需输出。通过酶促反应,这些 DNA 活字能被准确构建成长链 DNA。
这个过程中无需重新合成任何碱基序列,大幅提升了效率。第三步是存储。这些组装完成的 DNA 并不会被直接冷冻保存,而是被进一步克隆到质粒中。质粒是一种天然存在于细菌体内的小型环状 DNA 分子,常被用作实验载体。
研究人员将构建好的 DNA 片段插入到质粒中,再将其导入到大肠杆菌细胞之中。细胞在自然生长繁殖的同时,也会不断复制所携带的 DNA,从而实现稳定、低成本的生物存储与数据拷贝。最后一步是解码。
当需要提取数据时,只需对保存的 DNA 进行测序,识别其中包含的 DNA 活字序列,即可还原出原始的二进制内容,最终恢复出可读取的文件。为了提高系统的准确率,研究人员在每个片段中还设计了额外的校验信息,用于检测和修复可能的错误。
毕昇一号的工作流程(图片来源:参考文献[1])
给DNA装“活字” 我国自主研发“毕昇一号”实现存储技术跨越
值得一提的是,毕昇一号所使用的 DNA 活字全部由人工预先合成并存储在墨盒中。一旦合成完成,每个 DNA 活字可以反复使用上万次。这大幅降低了 DNA 存储的成本,也提高了存储效率。结语从雕版到活字,从纸张到 DNA,人类记录与储存信息的方式正在经历一场跨越千年的演变。
在当今大数据时代,我们不再满足于存储容量的缓慢提升,而是开始思索:能否将数据存储进 DNA 之中?毕昇一号借助 DNA 活字的创新形式,避免了反复合成的高昂成本,在效率和成本上取得了新的突破,展现了 DNA 存储技术的巨大潜力。
随着技术的进一步发展,或许在未来,我们的海量数据真的能被“写入”DNA,以生命的方式实现跨越时空的保存。
- 本文固定链接: http://4218.cn/articles/63093.html
- 转载请注明: zhiyongz 于 科技资讯 发表